
How does a Neuron Work in a Neural Network ? - Deep Learning Simplified Series


Today I started going through MIT's Intro to Deep Learning lectures and let me say you this - "They are really really good " .
I mean if you start the lecture by kicking it off with the former President of the USA - Barack Obama, welcoming the students obviously it's going to be good which by the way you find out later that it was just a GAN generated deep fake video which I think makes it even really really good and exciting. 😄
An awesome job by Alexander Amini explaining all the concepts with precision.
So, this is the first article of my Deep Learning Simplified Series and here I will be simply explaining how a simple neuron or perceptron in a neural network works in a very simple way. Let's get started !! 🔥
The Structure :
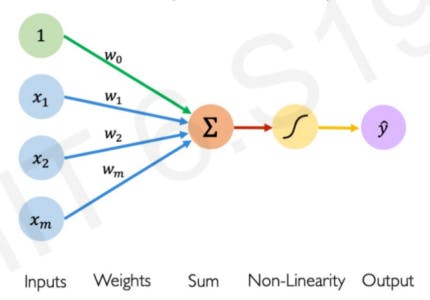
As labelled :
x = Inputs
y = Outputs
w = Weights / Parameters
The '1' in the input is called a bias input and for simplification purposes, we will ignore that.
The Formula :
This formula that forms a process of going from a set of inputs to a specific output is called Forward Propagation.
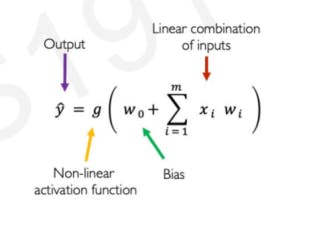
So, in simple words what's happening here is this :
INPUT
👇
✔ Dot Product of Input & Weights.
✔ Add the bias.
✔ Apply Non-Linearity.
👇
OUTPUT
Now if we further simplify the above equation to make the computation easier we can just convert all the inputs and weights into a vector and find out the dot product at once.
And that makes it looks like this :
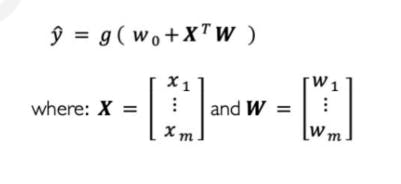
It's beautiful, isn't it! 🧡
So, now you must be wondering - Okay so what is an Activation Function? Don't worry here you go :
What is an Activation Function (g) ?
By definition, activation functions are mathematical equations that determine the output of a neural network. The function is attached to each neuron in the network, and determines whether it should be activated (“fired”) or not, based on whether each neuron's input is relevant for the model's prediction.
But the main point that I want you to understand is that these functions introduce Non-Linearity into the model which helps us solve crazy, complex & chaotic problems like Self-Driving Cars instead of just predicting the house price which is just a basic Linear Regression problem.
These graphs will make you really understand what I am saying :
So, let's assume our task is to predict where the next green dots and red dots will lie according to some data given to us which looks like this :
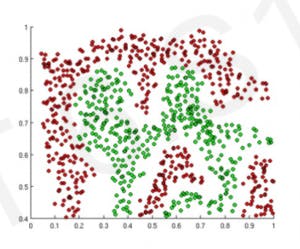
So, if our model will be able to differentiate between the Green and Red Points we are successful right.
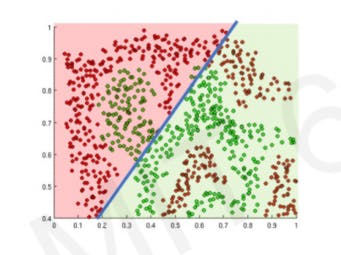
Now if for this task we just use a Linear activation function instead of a non-linear one we get something like this which is a pretty bad result :
But if we use a Non-Linear activation function this is what we get :
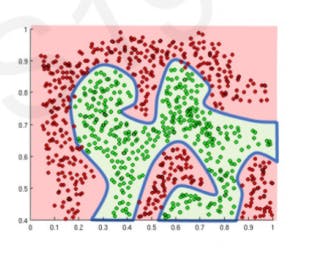
This happened because our model did not think just Linearly but also in a non-linear fashion.
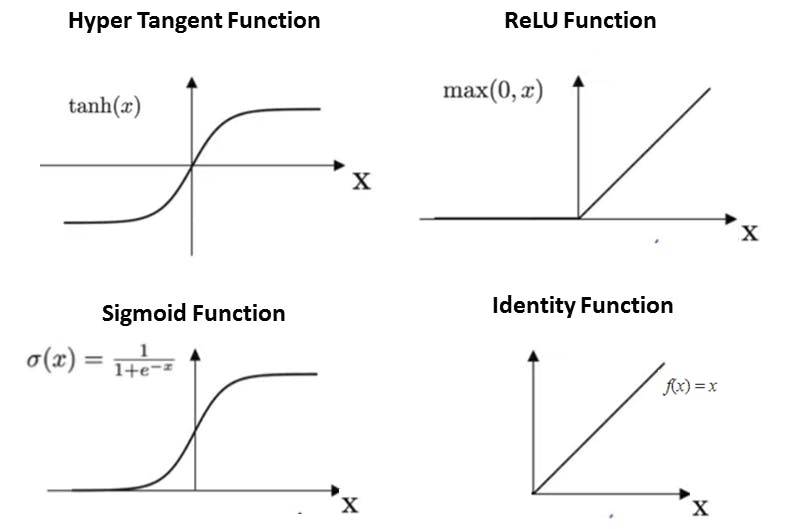
Examples of some activation functions used often in Machine and Deep Learning are :
We are at the end of this article and I just want you to remember these three simple steps :
- ✔ Find the Dot Product of Input & Weights.
- ✔ Add the bias.
- ✔ Apply Non-Linearity.
So, this was the first article of this Deep Learning Simplified series and I want lots of feedback on it to keep improving! 🙌
Comment your thoughts below !!
Let’s Connect :
🐦 Twitter : saumya4real
📹 Youtube Channel : FutureDriven
👨💻 LinkedIn : saumya66
🔥 GitHub : saumya66